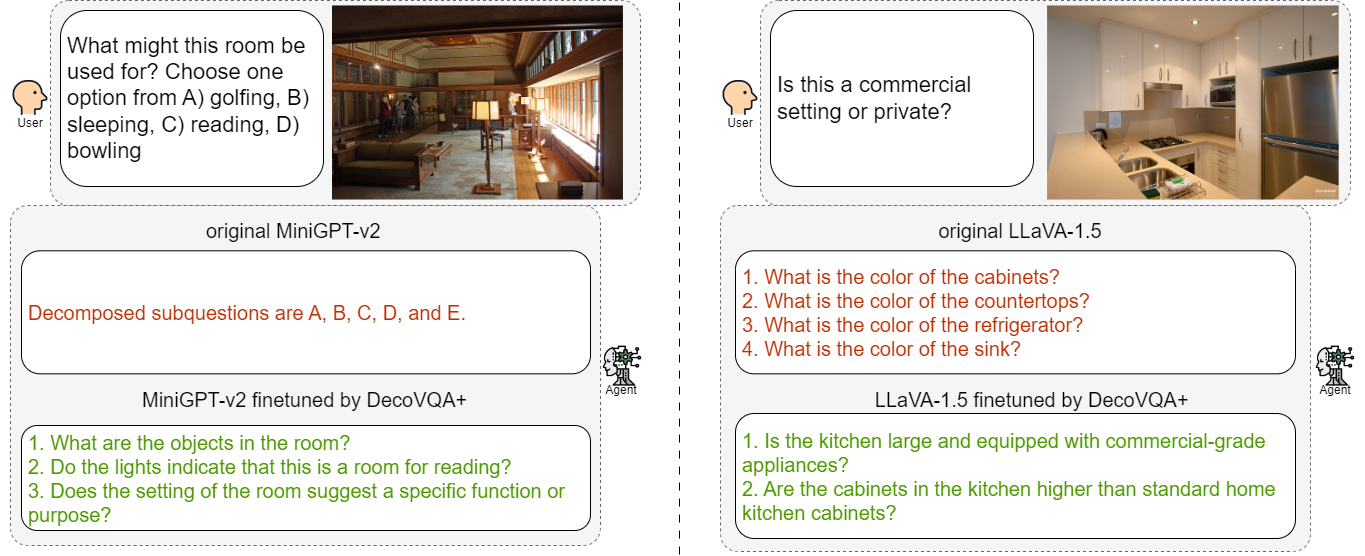
Comparison of the VQD ability before and after finetuning.
Abstract
Question decomposition has emerged as an effective strategy for prompting Large Language Models (LLMs) to answer complex questions. However, while existing methods primarily focus on unimodal language models, the question decomposition capability of Multimodal Large Language Models (MLLMs) has yet to be explored. To this end, this paper explores visual question decomposition on MLLMs. Specifically, we introduce a systematic evaluation framework including a dataset and several evaluation criteria to assess the quality of the decomposed sub-questions, revealing that existing MLLMs struggle to produce high-quality sub-questions. To address this limitation, we propose a specific finetuning dataset, DecoVQA+, for enhancing the model's question decomposition capability. Aiming at enabling models to perform appropriate selective decomposition, we propose an efficient finetuning pipeline. The finetuning pipeline consists of our proposed dataset and a training objective for selective decomposition. Finetuned MLLMs demonstrate significant improvements in the quality of sub-questions and the policy of selective question decomposition. Additionally, the models also achieve higher accuracy with selective decomposition on VQA benchmark datasets.
BibTeX
@misc{zhang2024visualquestiondecompositionmultimodal,
title={Visual Question Decomposition on Multimodal Large Language Models},
author={Haowei Zhang and Jianzhe Liu and Zhen Han and Shuo Chen and Bailan He and Volker Tresp and Zhiqiang Xu and Jindong Gu},
year={2024},
eprint={2409.19339},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2409.19339},
}